|
|
 14.1. Importare: filtri di conversione 14.1. Importare: filtri di conversione
Importazione filtri
Il filtri di conversione esistono come tali (Import Filters) ed anche incorporati dentro i file di connessione -Connection Files- con cataloghi esterni (siti remoti con database e cataloghi di biblioteche) perlopiù accessibili tramite protocollo Z39.50. A parte le indicazioni specifiche per collegarsi ad un server e per
interrogarlo, tutte le altre specifiche di configurazioni sono comuni sia a filtri di importazione che ai file di conversione e vengono descritte solo qui.
Entrambi -connections e import filters- hanno Templates che impostano una corrispondenza fra campo in entrata e campo di destinazione di EndNote con istruzioni di riconoscimento per il campo in entrata; questa componente è il cuore
di ogni importazione/conversione.
Inoltre EndNote automaticamente manipola certi campi in importazione, a monte delle specifiche che vediamo e possiamo alterare nei filtri, viene deciso nel codice del programma, si veda a proposito Campi dei record: annotazioni
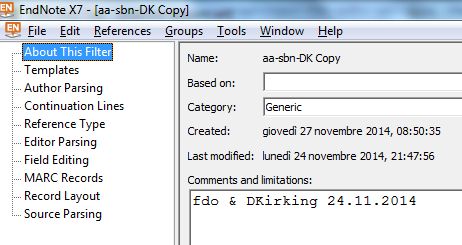
Figura 1 : filtri di conversione: | Edit | Import Filters (o Connection File)
|
About This Filter
Name: Mostra il nome del filtro di conversione come registrato nella cartella per i Filters della cartella di EndNote, ha estensione " .enf" che qui non viene mostrata. Il nome non può venire
cambiato qui ma sotto sistema operativo (Windows, Mac OS).
Based On: Ci si scrivono annotazioni utili a documentare come si è creato il filtro, quelli forniti da EndNote già ce l'hanno: ci si può anche scrivere l'URL di una pagina che contiene la documentazione dettagliata.
Category: La categoria è una classificazione domestica piuttosto che del nome del fornitore dei dati che il filtro serve a recuperare (come CSA, EBSCO, Dialog, Ovid etc.). Ha il suo valore diretto d'uso poiché ciò
(che sia Generic, Library Catalogs e quant'altro) compare anche come una colonna accanto al nome dentro il "Filter Manager" che permette di utilizzare tutta la lista dei filtri; e sui valori di questa colonna si può ordinare tutta la
lista e si può fare ricerca.
Created: La data automatica in cui è stato creato o aggiunto
Last Modified: Data automatica dell'ultima modifica
Comments and Limitations: commenti sul funzionamento del filtro, caveat ad libitum...
Tutto quanto scritto in questo pannello è anche visibile nella finestra del Filter Manager (Edit | Import Filetrs | Open File Manager). Per cui si possono consultare da lì queste
informazioni cliccando su 'More Info' senza dovere aprire un filtro in editazione, cosa che si fa comunque quando serve con 'Edit'. Dal Filter manager si possono ("Get More on the Web ...") andare a scaricare più filtri dal
sito di EndNote
|
 |
 Templates (cfr. Fig. 2 e 3) Templates (cfr. Fig. 2 e 3)
-
Come per gli stili di formattazione ci sono specifiche diverse per ogni RT (che viene prima selezionato nella finestrella in alto 'Reference Types", cfr. sotto Figura 3)
-
Prima colonna a sinistra della barra | il TAG del campo in ingresso (inclusi eventuali spazi che lo precedono)
Colonna a destra della barra | il Nome del campo EndNote di arrivo
-
Il pulsante Insert Field fa accedere a tutta la lista dei campi EndNote selezionabili col mouse; facilitando la redazione senza errori di scrittura) (cfr. sotto in Figura 3)
- Per omettere un campo in ingresso, o una sua porzione delimitata all'inizio da una stringa da indicare, specificare "{IGNORE}" come destinazione; nel caso di dati MARC un sottocampo non indicato viene automaticamente omesso (cfr. sotto
in Figura 2, es. 2 e 5)
- I TAG (a sinistra) fanno differenza fra maiuscolo e minuscolo (case sensitive)
-
Le stringhe che vengono indicate a destra -della barra rossa nei miei esempi di Fig. 2- sono presenti nei dati in ingresso e limitano i dati che vanno effettivamente importati: esse come tali vengono omesse (in
"Field editing" -vedi oltre- si possono indicare per ogni campo le stringhe da omettere a monte -ma NON da rimpiazzare o da aggiungere- e come trattare le maiuscole)
- Le stringhe presenti in ingresso ed identiche a nomi di campi EndNote (URL, Pages, Year ...) si mettono fra accenti gravi ASCII-96: `Journal` (cfr. sotto es. 1)
- Stringhe e campi di destinazione a destra sono scritti allo stesso modo e adiacenti, i nomi dei campi non sono blocchi-codici ma normali sequenze di caratteri (non aiuta i non esperti)
- Il TAG di un campo in ingresso può essere usato una sola volta; solo quello che indica l'RT può servire sia per identificare l'RT che per avvalorare un campo col suo contenuto
- Più campi in input possono essere 'fusi' (merging), inviati ad uno stesso campo EndNote
- Spesso su ogni singola riga va un solo campo in ingresso e uno in destinazione, ma non sempre, infatti ...
- Lo stesso 'unico' dato (TAG) in ingresso può finire in più campi a destinazione, l'istruzione per frammentarli va su una stessa linea (cfr. sotto es. 3 e 6): è così che vengono trattati i campi
compositi, da frammentare (parsing) ad es.:
- i campi MARC coi vari sottocampi,
- gli estremi del documento ospitante una parte, come un articolo di una rivista, un contributo ad un convegno ...: "titolo della rivista e/o anno, volume, fascicolo, pagine",
- "luogo editore ed anno di pubblicazione"
- ci possono poi essere più istruzioni per trattare lo stesso dato che si presenta in record diversi dello stesso file in ingresso in configurazioni varianti
-
- siccome un dato in ingresso in MARC può venire usato trattato una sola volta, a meno che non si tratti di quanto identifica l'RT, si cercherà di realizzare la frammentazione di diversi scenari di configurazione dei dati su una
sola medesima riga (cfr. sotto es. 6) ;
- lo si farà su linee diverse per dati non-MARC quando si stanno prevedendo più scenari, dal più completo ed articolato fino al più elementare, in modo da cercare di intercettare sempre i dati che si presentassero in arrivo anche
non secondo un unico schema (cfr. sotto es. 4 ).
Figura 2 : Righe di diversi Template di importazione
| 1 |
DT - | | `Journal` Article |
Riconoscimento del tipo di documento in arrivo per definire il RT dentro a EndNote; qui la barra verticale rossa | separa la colonna di sinistra da quella di destra:
a sinistra il TAG del campo in ingresso; a destra la destinazione, i campi, in EndNote e le stringhe in input che delimitano i dati e che vanno omesse |
| 2 |
ER - | | http:/{IGNORE}.org/DOI |
qui dunque la stringa di input che comincia con "http:/" viene omessa perché assegnata al campo '{IGNORE}', la stringa che segue ".org/" viene inviata al campo EndNote 'DOI' |
| 3 |
Source | Journal vVolume nIssue pPages Date| Year
|
In una linea di istruzione di frammentazione come la seguente, la -seconda- barra verticale (pipe ASCII |) dice a Endnote: tutto quanto segue le pagine ('Pages' che sono precedute da "p" nei dati in
ingresso) e fino alle 4 cifre che identificano l'anno Year va messo nel campo "Date"
|
| 4 |
Pub | || Publisher; City, Year
Pub | || Publisher, Year
Pub | || City, Year |
Uno stesso campo composito con stringhe -la punteggiatura- che delimitano dati con diversa destinazione. Siccome, per esperienza, in questo tipo di file i dati in ingresso si possono presentare in almeno 3 varianti in
record diversi, vengono preparate 3 linee di istruzione dalla configurazione più complessa alla più semplice |
| 5 |
200 | $aTitle$bTitle$cTitle$dTitle$eTitle$fNotes$g{IGNORE}$hTitle$iTitle$vTitle |
In questo altro esempio -tratto da un file di connessione a catalogo online- il contenuto del campo UNIMARC 200 (Titolo "proprio" etc.) viene riconosciuto nelle sue varie componenti, alcune delle quali -le formulazioni di
responsabilità di $f- vengono isolate e mandate nel campo Notes, quelle secondarie di $g vengono escluse, tutti gli altri sottocampi riconosciuti in base al loro codice vengono accodati nel campo 'Title' di EndNote; eventuali sottocampi
presenti nei dati in ingresso e qui non specificati verranno trascurati |
| 6 |
773 | $cNotes $dNotes $tJournal (Notes)$tJournal $gVolume, no. Issue (Date): Pages $gno. Issue (Date): Pages $gVolume (Date): Pages $gVolume (Date) $g(Date)
$gNotes $xNotes $yNotes |
come sopra in 4, più istruzioni per fare fronte a record varianti nello stesso file; qui però trattandosi di dati MARC le istruzioni vanno su una stessa linea e non su linee distinte: più varianti
per $c, $t e fino a 6 varianti per il sottocampo $g di 773 |
RT: il tipo di record/documento
Anzitutto va scelto un RT -ossia di un tipo di documento- di destinazione -nel Template nella finestrella in alto "Reference Types" - ad es. Electronic Book; in realtà EndNote userà questo come destinazione dopo avere riconosciuto un Tag di RT nel
file in input analizzando la lista sottostyante dei campi. Per identificare e condizionare la conversione alla presenza di un RT descritto nei record in input occorre infatti indicarne il "TAG" identificativo che lo precede nell'input file fra i
campi di arrivo in EndNote, quindi a sinistra nella colonna Tag (e il contenuto a destra).
Non c'è alcuna regola, ma spesso è una stringa come 'TY - ' 'DT - ' 'PT - ' 'Format', in MARC può stare come GMD General Material Designation dentro il campo 200 o 245 del titolo ...
A destra, nella colonna Field(s) come campo di destinazione c'è il suo contenuto -che è fisso nei vari record dello stesso tipo e che è un nome che però non verrà importato. Il dato è invece variabile nei record se lo
stesso file di input contien record con diversi RT.
Non è necessario che il Tag dello RT sia il primo a venire elencato.
Se il nome del tipo di documento (il "contenuto" del TAG di RT) contiene termini che ricorrono anche come nomi di campi (o solo parte dei campi) di EndNote occorre inserire questa/e parola fra accenti gravi (ASCII 96 = `), esempi vari possibili in file diversi e in record diversi :
Format: | `[Manuscript]`
DT - | `Journal` Article
%0 - | `Journal`
Article
245 | `computer file`
245 |
`[Manuscript]`
Livello bibliografico | `Monografia`
Tipo documento | `BOOK`
Se non c'è un RT esplicitabile nel file di input, verrà usato quello di default indicato nel filtro in Default Reference Type, cfr. sotto in Fig. 6.
L'RT si specifica più volte anche nello stesso Template sia, come detto, quando è presente nel file di input con diversi valori (i.e.: uno stesso file contiene record con diversi tipi di documento) e quando si vuole usarlo non solo per
l'attribuzione del tipo di documento, ma anche per salvarne il contenuto in un campo EndNote.
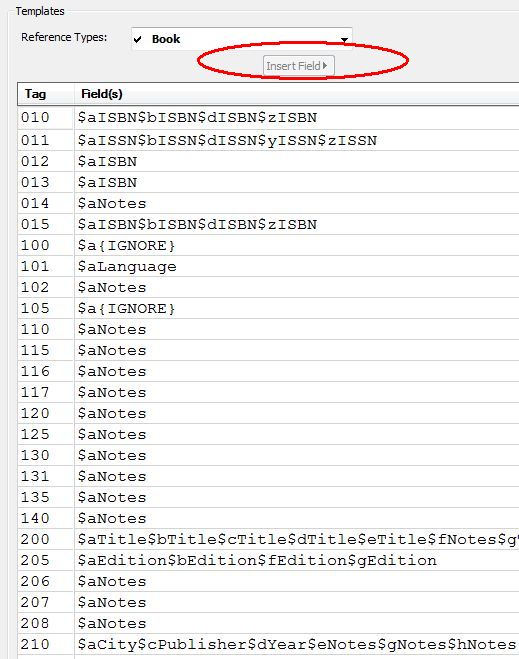
Figura 3 : Templates di 2 diversi filtri di conversione per 2 RT : Book, Journal Article
Book : ripartito in una colonna di sinistra = input: Tag) e in una di destra = Field(s)
destinazione + stringhe delimitanti i sottocampi i ingresso |
 |
| Journal Article, idem: ripartito in una colonna di sinistra Tag = destinazione e in una di destra Field(s) |
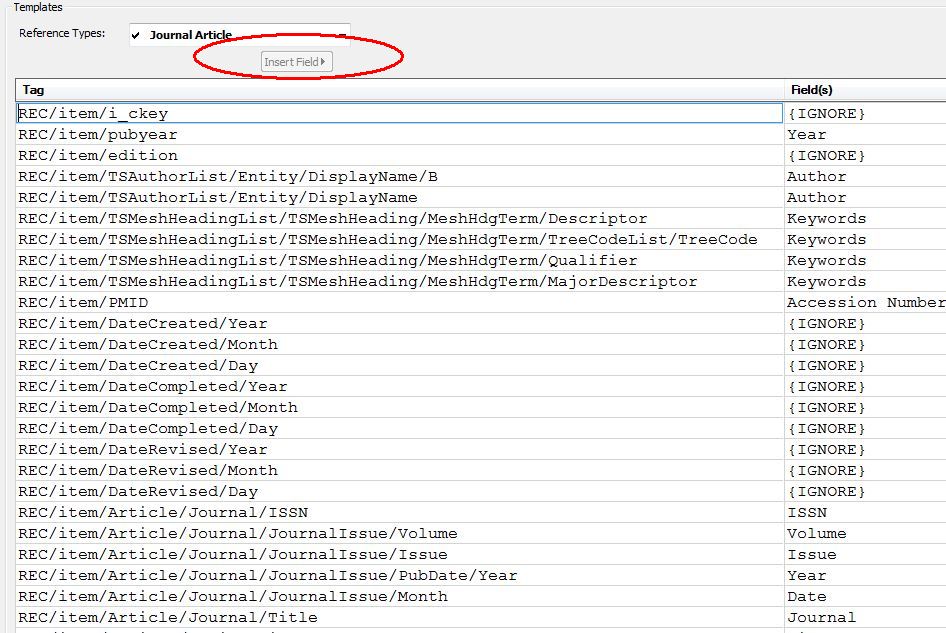 |
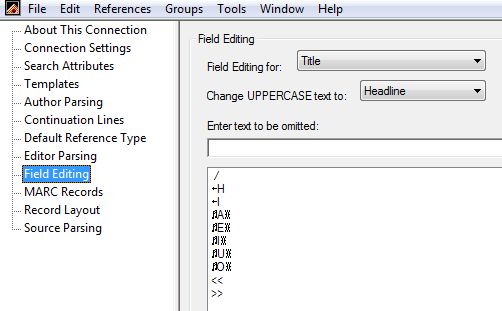
Figura 4 : Specifiche di conversione in importazione, es.: (A) Field Editing (B)
Author Parsing
| (A) Filtro di conversione interno a un file di connessione (Connection File): specifiche per omettere stringhe dai campi in ingresso |
(B) Filtro di conversione come Import Filter: specifiche per riconoscimento e trattamento dei nomi degli autori |
| Field editing: per ogni campo si possono indicare più stringhe da omettere, non da sostituire o da aggiungere. Si trattano anche testi TUTTI in maiuscolo riducendoli, se si vuole, a una delle 3 opzioni
previste |
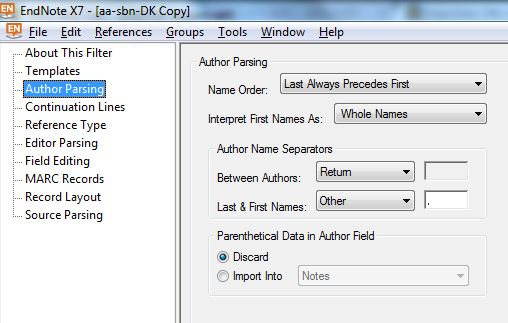
Author Parsing : Particolarità: Come trattare Corporate names in ingresso che, venendo da EndNote dovrebbero avere una virgola alla fine? Come conservare elementi qualificativo-parentetici dei nomi di persona, o nomi in
forma diretta? Specificare nel filtro che per i nomi EndNote non deve fare nulla, ma importarli "As it is", dopodichè certo non ci si potrà attendere che usi invece il riconoscimento 'Smart' per capovolgere ed intromettere una virgola in un
mome scritto come : "Gianni Letta", cosa che saprebbe fare, si dovrà intervenire puntualmente a mano. Si può spesso fare affidamento al riconoscimento Smart, ma se i dati prevedono nomi non semplicemente composti di "cognome, nome" ciò
non basterà.
Un pannello simile è poi offerto anche per lo Editor Parsing |
 |
 |
| Figura 5 : Come trattare le linee che vanno a capo, indentate o meno |
|
 |
Continuation Lines
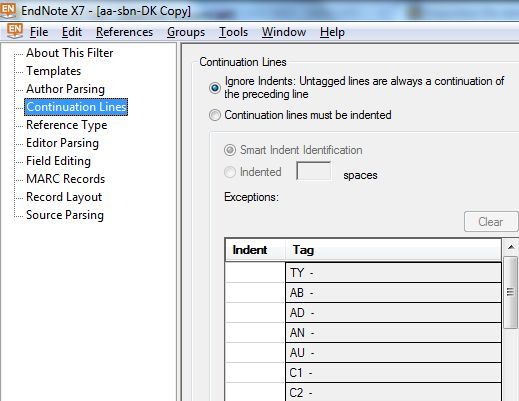
Serve a dire se una nuova linea è in realtà la continuazione della precedente e non un nuovo campo. Si specifica se la stessa linea che continua prevede un rientro, indentazione, oppure no ed è l'assenza di TAG che fa
interpretare una nuova linea come la coda della precedente. Si possono anche indicare i numeri di colonne/caratteri che compongono l'indentazione di ogni singolo campo, se i rientri per i vari campi sono irregolari |
| Figura 6 : RT di default |
|
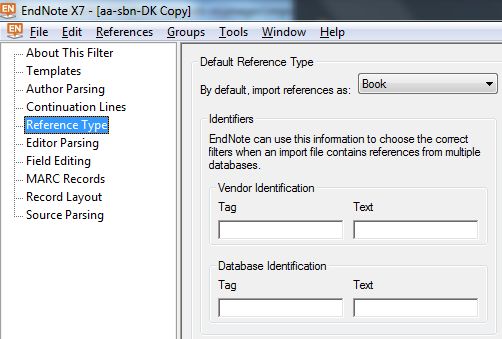 |
Reference Type: Serve ad indicare l'RT di default, e quelli particolari se un file ne contiene più di uno, quando mancano stringhe identificanti l'RT quali quelle descritte qui in precedenza |
| Figura 7 : Specifiche per i file con record in MARC |
£ |
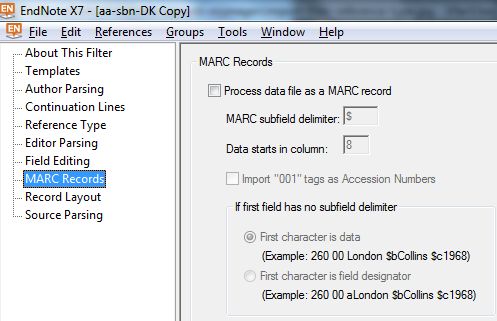 |
Marc Recors : Si tratta di indicazioni per il trattamento di record in MARC -comunque ad etichette- ma con TAG numerici, appartenenti allo standard del MARC in questione (MARC21, UNIMARC etc. etc.). Il
TAG del template considererà solo i TAG numerici a 3 cifre, gli indicatori non vengono presi in considerazione e i codici e separatori di sottocampi sono trattati come stringhe di caratteri che delimitano i dati contenuti e dunque vanno
nella parte di destra del template; qui si può specificare in generale che si tratta di un file con dati MARC, con uno specifico delimitatore di sottocampi, coi dati che cominciano in colonna n e se certi campi non hanno
sottocampo iniziale.
Ma in particolare tutto si farà nel Template, cfr. in prec.
|
| Figura 8 : Indicazioni circa l'aspetto globale di un record |
|
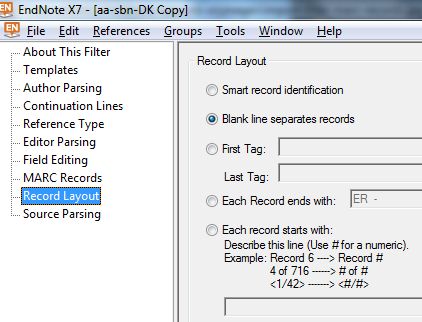 |
Record Layout : Come identificare l'inizio/fine dei record entro il medesimo file. C'è l'identifcazione 'Smart' lasciata ad EndNote o invece quella affidata a una nostra selezione fra 4 altre opzioni |
| Figura 9 : Indicazioni circa il campo "Source" |
|
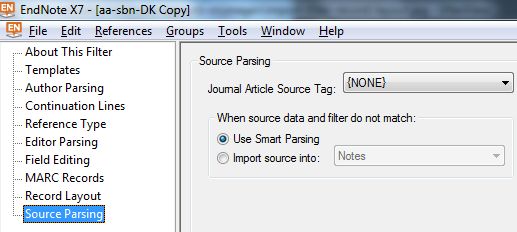 |
source Parsing : Indicazione per il campo che contiene il titolo della rivista e/o numero di volume/annata, fascicolo, pagine, anno.
Vale solo per l'RT Journal Article e per lasciare agire gli automatismi di EndNote.
Il file MARC non si avvale di questa impostazione, richiede solo che un campo "Source" venga analiticamente trattato nel Template. |
|

