|
ESB Forum
ISSN: 2283-303X |
||
I cataloghi elettronici delle bibliotecheTendenze evolutive degli OPACTesi di laurea in biblioteconomia, Corso di laurea in Conservazione dei Beni Culturali, Facoltà di Lettere e Filosofia dell'Università Ca' Foscari di Venezia, relatore prof. Riccardo Ridi, correlatore prof. Paolo Eleuteri, anno accademico 2006/2007 discussa il 27 febbraio 2008. di Lucia Tronchin (in linea da marzo 2008) 6. Opac 2.06.1 Web 2.0Recentemente anche le biblioteche sono state investite dalle spinte innovative che provengono da quello che viene definito Web 2.0. Secondo Tim OReilly (OReilly 2005a) questo termine è stato coniato nel 2004 da Dale Dougherty, vicepresidente della OReilly Media Inc.[1], durante un incontro nel quale si discuteva del futuro del Web dopo il boom e il successivo fallimento di molte aziende che operavano in internet, le così dette dot-com. Queste aziende, che offrivano i loro servizi quasi esclusivamente attraverso la rete, erano nate nel corso degli anni novanta e avevano attirato una grande quantità di capitali e speranze in quella che veniva definita new economy, finendo però, per la maggior parte, in un rovinoso crollo che ha avuto il suo punto più basso nellautunno del 2001. Secondo Dougherty quel crollo segnava un punto di svolta nella rete che andava indagato per capire quale nuova direzione intraprendere. Analizzando le aziende che erano sopravvissute, e le nuove che nonostante la crisi si imponevano sul web, si potevano notare delle caratteristiche comuni nelle applicazioni sviluppate e nelle strategie aziendali, caratteristiche così peculiari e sostanzialmente differenti dalla logica operante fino ad allora nel web da giustificare, per il loro insieme e per la nuova direzione che doveva prendere lazione sul web, il conio dellespressione Web 2.0. OReilly sostiene che nel momento in cui egli stava scrivendo il suo articolo, quindi ad un anno e mezzo dalla sua prima formulazione, esistevano su internet 9,5 milioni di citazioni per il termine Web 2.0, e riteneva pertanto necessario chiarire che cosa si dovesse intendere con questa espressione. Egli ne descrive le caratteristiche raggruppandole intorno a sette principi: il Web come piattaforma, sfruttare lintelligenza della folla, i dati sono il prossimo Intel inside, la fine del ciclo delle release di software, modelli di programmazione leggeri, il software supera il livello del singolo dispositivo, esperienze ricche per lutente (OReilly 2005a). Una sua successiva definizione tenta di sommarizzare i concetti Web 2.0 is the network as platform, spanning all connected devices; Web 2.0 applications are those that make the most of the intrinsic advantages of that platform: delivering software as a continually-updated service that gets better the more people use it, consuming and remixing data from multiple sources, including individual users, while providing their own data and services in a form that allows remixing by others, creating network effects through an "architecture of participation," and going beyond the page metaphor of Web 1.0 to deliver rich user experiences (OReilly 2005b)[2]. Nonostante alcuni di questi principi siano strettamente legati alla comparazione dei modelli aziendali e di produzione del software, il riferimento a concetti come intelligenza collettiva, saggezza delle folle, architettura partecipativa li fa uscire dallambito tecnico per entrare nel campo della filosofia della rete, del modo in cui le persone e le idee interagiscono e si evolvono in un ambiente di network. Questi aspetti hanno saputo suscitare interesse in ambienti anche molto lontani da quello tecnico-informatico dando vita a tendenze, a movimenti di idee che nel nome e nella visione si riferiscono a Web 2.0 intendendolo come una rivoluzione, un cambiamento tecnologico che ha significative ricadute sociali[3]. OReilly limita laspetto rivoluzionario al campo del business, Web 2.0 is the business revolution in the computer industry caused by the move to the internet as platform, and an attempt to understand the rules for success on that new platform. Chief among those rules is this: Build applications that harness network effects to get better the more people use them. (This is what I've elsewhere called "harnessing collective intelligence.") (OReilly 2006)[4], tuttavia la discussione se Web 2.0 sia una rivoluzione nel nostro approccio a internet, una nuova bolla tecnologica o solo una moda, continua in internet e anche sugli altri media. A distanza di tre anni dalla sua prima formulazione le citazioni di Web 2.0 in internet si sono decuplicate e non cè rivista o giornale che non si sia occupato dellargomento. Le prospettive da cui si guarda alla questione e le opinioni in merito sono naturalmente diverse a seconda se chi ne parla è unazienda che deve competere sul mercato con i suoi prodotti, un acquirente, un commentatore di costume o un appassionato di nuove tecnologie. In questo contesto può forse essere utile conoscere unopinione autorevole come quella di Tim Berners-Lee, linventore del Web. In un interessante rapporto in cui analizza le implicazioni dei concetti e delle tecnologie di Web 2.0 per le istituzioni educative della Gran Bretagna Paul Anderson cita unintervista di Berners-Lee pubblicata come podcast sul sito della IBM nellagosto del 2006 (Anderson 2007). Alla domanda se il Web 2.0 possa essere considerato diverso da quello che ora potrebbe essere chiamato Web 1.0 perché il Web 2.0 è tutto concentrato nel mettere in relazione, nel connettere le persone egli risponde Totally not. Web 1.0 was all about connecting people. It was an interactive space, and I think Web 2.0 is of course a piece of jargon, nobody even knows what it means. If Web 2.0 for you is blogs and wikis, then that is people to people. But that was what the Web was supposed to be all along. And in fact, you know, this 'Web 2.0', it means using the standards which have been produced by all these people working on Web 1.0.[5] Secondo Anderson la posizione di Berners-Lee può essere compresa guardando alla storia dello sviluppo del rete. Berners-Lee aveva in mente uno spazio di lavoro collaborativo in cui tutto era connesso a tutto in un unico ambiente informativo globale nel quale ognuno aveva la possibilità di pubblicare. Nel suo libro Weaving the Web del 1999 (Berners-Lee-Fischetti 1999) egli spiega come lavorando al CERN avesse sviluppato una prima applicazione che consentiva di linkare insieme e pubblicare degli appunti. Uno sviluppo seguente fu la creazione del Worl Wide Web e di un browser, cioè di un client del web, che consentiva di visualizzare e pubblicare pagine in un linguaggio di marcatura (html). Nel passaggio dal computer di sviluppo ad altre macchine, per velocizzare ladozione delle nuove applicazioni in seno al CERN, la possibilità di pubblicare sul web non fu inclusa. Di conseguenza questa funzione di edit non passò nei browser successivi, Viola WWW e Mosaic che poi diventò il browser di Netscape. Questo ha dato lidea che il Web fosse uno strumento nel quale pochi pubblicano e molti navigano. Sarebbe invece più corretto dire che ad un certo punto dello sviluppo tecnologico la strada si è biforcata e che solo recentemente si è ricongiunta e che certe tecnologie hanno richiesto più tempo per essere pienamente sviluppate di quanto fosse stato previsto. Secondo Anderson si dovrebbe dunque pensare al Web 2.0 non in opposizione al Web 1.0 ma come il risultato di una maggiore attuazione dei principi del Web 1.0. Va detto che anche OReilly riconosce a Berners-Lee il suo ruolo Ironically, Tim Berners-Lee's original Web 1.0 is one of the most "Web 2.0" systems out there --it completely harnesses the power of user contribution, collective intelligence, and network effects. It was Web 1.5, the dotcom bubble, in which people tried to make the web into something else, that fought the internet, and lost (OReilly 2006)[6]. Nel suo rapporto Anderson, dopo aver esaminato le applicazioni più caratteristiche di Web 2.0, (blogs, wikis, taggin e social bookmarking, folksonomy e cullaborary, multimedia sharing, audio bloggin e podcasting, RSS e syndication) e le categorie di servizi che su queste applicazioni si possono costruire (social networking, aggregation services, data mash-ups, tracking and filtering content, collaborating, replicate office-style software in the browser, source ideas or work from the crowd) (Anderson 2007 pag. 7-13) descrive quelle che secondo lui sono le idee fondamentali alla base di Web 2.0 facendo riferimento ai principi espressi da OReilly (OReilly 2005a). Vedremo in seguito come queste idee abbiano un impatto sulle biblioteche e sugli opac.
Produzione individuale e contenuti generati dagli utenti La barriera tra chi produce e chi usa contenuti è venuta sgretolandosi già dagli anni 80 con i primi prodotti software di desktop publishing e le prime stampanti laser da ufficio che hanno reso possibile stampare testi di sufficiente qualità senza dover necessariamente passare attraverso lintermediazione delle case editrici le quali hanno smesso di costituire il filtro, lautorità che stabilisce ciò che può essere stampato e ciò che non lo è. Allo stesso modo oggi è possibile produrre i propri cd musicali, i propri filmati, i propri commenti, le proprie informazioni e pubblicarli sul web con tecnologie semplici che rendono tutti produttori di contenuti oltre che consumatori. Questo fa sì che nelle persone sia molto cambiata la percezione di chi ha lautorità e la capacità di dire, di scrivere, di esprimersi. Secondo Anderson questo costituisce una sfida alle istituzioni di tipo educativo le quali si trovano davanti giovani abituati al confronto tra pari ai quali devono invece trasmettere idee di gerarchia nella produzione e nellautenticazione della conoscenza, oltre che affrontare i problemi legati alla privacy, al plagio, ai diritti dautore (Anderson 2007 pag. 33). Come vedremo, questo aspetto è significativo anche per le biblioteche.
Sfruttare il potere della folla Questo concetto, inizialmente espresso da OReilly come Sfruttare lintelligenza collettiva, fa riferimento al libro Wisdom of the crowds di James Surowiecki (Surowiecki 2004). Il libro dimostra come alcuni tipi di problemi possono essere risolti in modo più efficace da gruppi che lavorano in specifiche condizioni piuttosto che da singoli individui anche molto intelligenti. Lidea è che agendo in modo indipendente ma collettivamente la folla, in certe condizioni, abbia più probabilità di fornire la giusta risposta ad un problema di quante ne abbia il singolo individuo. Nonostante il libro faccia riferimento a specifiche situazioni e condizioni, e nonostante sostenga che non tutti i gruppi sono saggi e indipendenti, il suo stesso sottotitolo, Why the Many Are Smarter Than the Few and How Collective Wisdom Shapes Business, Economies, Societies and Nations, ha indotto ad estendere e generalizzare il concetto al di là delleffettivo contenuto del libro. Secondo Anderson questo libro ha avuto una grande influenza sul modo di pensare Web 2.0 e molti hanno adattato il pensiero di Surowiecki alle loro osservazioni circa le attività legate ad Internet, nonostante in molti casi più che di saggezza collettiva si dovrebbe parlare di produzione collaborativa (crowdsourcing). Legati al concetto di saggezza della folla sono i concetti di folksonomy e social tagging che hanno notevole risonanza anche nellambito delle biblioteche e dei loro cataloghi.
Dati su scala epica La nostra è definita lepoca dellinformazione: unenorme quantità di dati che per essere usata ha bisogno di essere incanalata. Secondo OReilly (OReilly 2005a) è la competenza a raccogliere e gestire questi dati in rete il core business delle aziende Web 2.0. Google ha attualmente un insieme di database che possono essere misurati in centinaia di petabyte che aumentano ogni giorno di molti terabyte[7] di nuova informazione generata dagli effetti del suo uso in ambiente di network. Molta di questa informazione è recuperata indirettamente dagli utenti e aggregata come effetto secondario delluso dei principali servizi e applicazioni internet come Google, Amazon e e-Bay. In un certo senso si può dire che questi servizi imparano ogni volta che vengono usati: ogni scelta di acquisto è aggregata a milioni di altre scelte, sottoposta a processi di data mining e utilizzata per fornire suggerimenti mirati per futuri acquisti a specifici target di utenti. Un altro aspetto significativo legato ai dati è quello che viene definito mash-up. Consiste nella possibilità di includere dinamicamente informazioni o contenuti provenienti da più fonti per creare un nuovo servizio web. Questa attività e resa possibile dalluso di API (Application programming Interfaces) aperte e di feed (es. RSS e Atom). Come vedremo, entrambe queste idee possono trovare applicazioni negli opac.
Architettura di partecipazione Si parla di unarchitettura di partecipazione quando attraverso il normale uso di unapplicazione o di un servizio, il servizio stesso migliora. Per lutente questo può essere visto come un effetto secondario delluso del servizio stesso ma in realtà il sistema è stato progettato specificamente per utilizzare le interazioni degli utenti e sfruttarle per migliorare il sistema stesso. Questa idea è quindi associata a quella di UGC (user generate content) ma ne sottolinea laspetto tecnico. Non significa semplicemente ridurre le barriere tra produttori e consumatori, incentivare la produzione di contenuti, facilitare a tutti luso dei servizi e delle applicazioni per aggiungere valore, ma creare architetture di sistema che, indipendentemente dalla volontà degli utilizzatori, sfruttino luso per aggiungere valore.
Effetti di rete Il Web è una rete di nodi interconnessi costruiti sulle tecnologie e i protocolli di internet che formano una rete di telecomunicazioni. Ora che la rete è usata da milioni di persone capire la topologia del Web e di internet, la sua forma, la sua interconnettività è importante per comprendere gli effetti e le implicazioni sociali del lavorare in questo ambiente. Un concetto significativo che ha a che fare con le dimensioni della rete e lutilità di aggiungere sempre nuovi utenti, è quello di Effetto di rete. Il concetto di effetto di rete è usato in campo economico per descrivere laumento di valore, per un singolo utente, di un servizio nel quale ci sia una forma di interazione con altri, quando un numero crescente di persone comincino ad usare quello stesso servizio. Può trattarsi di un effetto diretto quando il vantaggio di adottare un bene o un servizio aumenta se aumentano coloro che scelgono quello stesso bene o servizio (tipicamente quando scelgo una compagnia telefonica che ha molti altri utenti e posso quindi entrare in contatto con un numero maggiore di persone), oppure indiretto quando il beneficio consiste in una positiva ricaduta sul mercato di quel bene (quando acquisto un prodotto molto diffuso posso aspettarmi che venga migliorato se ha un bacino di utenti abbastanza ampio da giustificare linvestimento necessario al suo miglioramento). Stabilire quanto sia grande questo effetto di rete è di notevole importanza dal punto di vista economico. Un'eccessiva valutazione di questo effetto applicato ad Internet ha portato ad un'abnorme e artificiale stima del valore delle aziende della new economy e alla relativa bolla speculativa (Briscoe-Odlyzko-Tilly 2006). Nonostante questo lidea che ci sia uno speciale effetto nel lavorare in Internet dovuto alle caratteristiche della rete, alla sua vastità e topologia, è ancora molto forte tanto da poter essere considerata uno dei paradigmi nel campo dellinformation tecnology (Castells 2000). Molte delle applicazioni Web 2.0 hanno una natura sociale e sono costruite sulla speranza di godere dei benefici degli effetti di rete, specie quelli che potremo definire di tipo comportamentale, legati alle mode, alla tendenza umana a incanalarsi sui sentieri tracciati da altri. Un aspetto negativo delleffetto di rete, che può essere significativo anche per le istituzioni pubbliche, è il rischio di restare intrappolati nelluso di un prodotto che si sia così diffuso da rendere difficile lopzione di adottare un prodotto diverso. Per evitare questo rischio diventa fondamentale la ricerca di interoperabilità nella scelta delle tecnologie, dei prodotti, degli standard. Oltre agli effetti di network che dipendono dalla struttura di internet esistono effetti di network che dipendono dai legami che si creano tra diverse parti del Web in quanto contenuto. Leffetto di rete aumenta tanto più gli utenti contribuiscono con i loro contenuti o utilizzando servizi che aggregano dati. Questi effetti guidano il miglioramento dei servizi e delle applicazioni Web 2.0 come abbiamo visto parlando dellarchitettura di partecipazione. Unaltra caratteristica riconosciuta delle rete è quella di essere governata da una power law distribution. Una power law distribuition è rappresentabile su un piano cartesiano come una curva che partendo da un punto alto nellasse delle ascisse, scende rapidamente disponendosi in modo quasi parallelo allasse delle ordinate allungandosi allinfinito senza raggiungere lo zero. Questo implica che piccoli valori sono estremamente comuni mentre valori ampi sono estremamente rari. Questa caratteristica è stata studiata da Chris Anderson (Anderson 2006) il quale la applica non solo alle interconnessioni fisiche di internet e alle interconnessioni virtuali dei link ipertestuali ma anche alle interazioni che avvengono utilizzando gli strumenti disponibili in rete portando esempi legati in particolare al mondo delle vendite di album musicali. In un ambiente digitale, in cui non ci sono più i limiti fisici che costituiscono un ostacolo alla possibilità di scelta, le persone possono avere sempre a disposizione un numero virtualmente illimitato di prodotti da acquistare, non solo i pochi pubblicizzati o promossi negli scaffali fisici di un negozio. Questi prodotti sono rappresentati dai valori bassi che si distribuiscono lungo quella che Anderson chiama la lunga coda. La somma delle vendite di questi prodotti, che possiamo definire di nicchia, ha una rilevanza economica significativa che, in ambiente digitale, supera quella dei prodotti nuovi che si posizionano per un breve tempo nella parte alta della curva. Secondo Anderson questo significa che le persone con interessi specialistici e di nicchia cominciano a contare anche da un punto di vista economico. Questo favorisce tanto la libertà di scelta, lespressione di gusti originali e non conformisti, quanto la democratizzazione dei mezzi di produzione con la possibilità per i dilettanti immettere nel mercato le loro produzioni, cessando di essere solo consumatori. La teoria di Anderson ha avuto grande risonanza nel mondo delle biblioteche.
Apertura Il web ha sempre portato con se lidea di essere un ambiente aperto e questa idea si è rafforzata nel Web 2.0: lavorare con standard aperti, usare open source software, fare uso di dati liberi, riusare i dati e lavorare con spirito di innovazione. Cè, tuttavia, un grande dibattito su che cosa sia in realtà questa apertura. Al di la del concetto di software open source o delluso di API (Application Programming Interface) che non richiedono il pagamento di licenze o di royalty sembra che il concetto di apertura debba applicarsi piuttosto al contesto dei servizi Web-based: per questi servizi non è il software ma i dati che devono essere aperti. Relativamente ai dati nascono problematiche connesse al modo non standard in cui sono raccolti ed aggregati dalle aziende commerciali e al fatto che non sempre lapertura è bidirezionale: molte applicazioni non consento di esportare dati tanto facilmente quanto importarli. Inoltre, per poter parlare di dati aperti, le applicazioni dovrebbero consentire a chi ha immesso dati di riaverli indietro con la certezza che non siano trattenuti per futuri usi: questo non è attualmente garantito, cosa che ha notevoli ripercussioni sulle problematiche della privacy. Il tema dellapertura dei dati ha suscitato un ampio dibattito sia per quanto riguarda luso dei dati raccolti da agenzie pubbliche, sia rispetto ai dati prodotti in ambito accademico e scientifico. Naturalmente le idee e le applicazioni Web 2.0 legate al concetto di openness hanno una ricaduta enorme sul diritto dautore e su come esso è percepito sul Web.
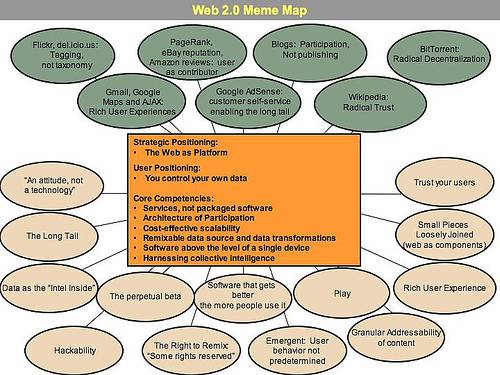
6.2 Library 2.0I was reading stuff about something called «Library 2.0»but the posts and items didnt seem to cohere. I thought I could gather some statements, print them out, read them through, provide excerpts and commentary, and maybe make sense of the whole thing [ ] the more I read about Library 2.0 the more confused I gotand the more I felt the need for a broad overview not written by an advocate or evangelist (Crawford 2006 pag. 1)[8]. Sulla spinta di questa difficoltà di comprendere il senso di Library 2.0 Walt Crawford ha scritto un corposo articolo (Crawford 2006) nel quale ha raccolto ben 7 definizioni e 62 opinioni diverse, spesso mutualmente opposte, su questo concetto nato sulla scia di Web 2.0. Due sono gli aspetti principali toccati in queste definizioni: il rapporto tra Library 2.0 e la tecnologia e quello tra Library 2.0 e il complesso dei servizi offerti dalle biblioteche, potremo dire la filosofia che sottende ai servizi delle biblioteche. Una visione più ristretta semplicemente identifica Library 2.0 con lappropriazione da parte delle biblioteche dei concetti e delle tecnologie di Web 2.0, ma sembra prevalere una visione più ampia che identifica Library 2.0 con una presunta nuova filosofia di servizio, anche se viene costantemente sottolineato che è la tecnologia Web 2.0 a guidare, a dare la direzione del cambiamento. Le prime tre definizioni analizzate da Crawford sono state scritte da Michael Casey per la voce della Wikipedia[9] Library 2.0 is a model for library service that reflects a transition within the library world in the way that services are delivered to library users. This redirection will be especially evident in electronic offerings such as OPAC configuration, online library services, and an increased flow of information from the user back to the library. The concept of Library 2.0 borrows from that of Web 2.0, and follows some of the same philosophies underpinning that concept. Proponents of this concept expect that ultimately the Library 2.0 model for service will replace outdated, one-directional service offerings that have characterized libraries for centuries[10]. Library 2.0 sees the reality of our current user-base and says, «not good enough, we can reach more people.» It seeks to do this through a three-part approachreaching out to new users, inviting customer participation, and relying on constant change. Much of this is made possible thanks to new technologies, but the services will only be partially tech-based[11]. L2 is, to me, a service philosophy built upon three things; a willingness to change and try new things; a willingness to constantly re-evaluate our service offerings; and finally, a willingness to look outside our own world for solutions, be they technology-driven or not (this is where Web 2.0 fits in)[12]. Come si vede, in queste definizioni la tecnologia non sembra essere il fattore dominante: sono enfatizzati piuttosto un nuovo modello nellerogazione dei servizi, un diverso atteggiamento verso lutente, una generica attitudine al cambiamento. Casey ritiene gli attuali servizi delle biblioteche caratterizzati dalla unidirezionalità e perciò obsoleti. Il nuovo atteggiamento dovrebbe essere quello di rivalutare costantemente lofferta di servizi, cercare sempre nuovi utenti e invitarli alla partecipazione per creare un flusso informativo che sia non solo dalla biblioteca verso lutente ma anche dallutente alla biblioteca. Sostenere che le biblioteche siano state per secoli lontane da un atteggiamento di attenzione alle necessità degli utenti, non abbiano cercato nuovi utenti, non abbiano costantemente almeno tentato di fare uno sforzo per valutare la congruità dei propri servizi, non siano state aperte al cambiamento, mi sembra una posizione indifendibile. La loro storia e il fatto stesso che esistano da un paio di millenni mi sembrano sufficienti a dimostrarlo. Ma esse sono istituzioni sociali (Petrucciani 2004 pag. 204) e come tali hanno svolto funzioni differenziate nel tempo e nello spazio adattandosi ai diversi contesti mantenendo le loro caratteristiche fondamentali. Il punto che fa la differenza sembra essere allora il discorso sulla direzione del flusso informativo, sul ruolo attivo dellutente. In una biblioteca che sposasse i principi di Library 2.0 gli utenti[13] dovrebbero essere collaboratori, avere un ruolo attivo nel definire i servizi della biblioteca, dovrebbero poter adattare i servizi per farli coincidere al meglio con le proprie necessità. Questo potrebbe essere fatto elettronicamente, consentendo la personalizzazione delle pagine web della biblioteca, ma anche fisicamente consentendo agli utenti di indire incontri estemporanei o gruppi di discussione sui libri in biblioteca. La biblioteca dovrebbe utilizzare la conoscenza degli utenti per migliorare i servizi facilitando commenti, tags, valutazioni, che potrebbero essere svolti attraverso uninterfaccia dellopac più versatile. Queste attività degli utenti migliorerebbero il catalogo e produrrebbero informazioni riutilizzabili dai futuri utenti incrementando la qualità del servizio (Casey-Savastinuk 2006). Anche la definizione di Sarah Houghton enfatizza la necessità di dare agli utenti un ruolo attivo. Library 2.0 simply means making your librarys space (virtual and physical) more interactive, collaborative, and driven by community needs. Examples of where to start include blogs, gaming nights for teens, and collaborative photo sites. The basic drive is to get people back into the library by making the library relevant to what they want and need in their daily lives...to make the library a destination and not an afterthought (Houghton 2005)[14]. In questa definizione compare il tema della rilevanza della biblioteca. Il timore che la biblioteca diventi irrilevante per gli utenti, specie quelli più giovani, spinge a cercare di fornire servizi che possano riportare gli utenti in biblioteca fornendo risposte a tutte le loro necessità. Sthephen si spinge ad affermare che la Library 2.0 dovrebbe essere un luogo di incontro, fisico o virtuale, nel quale vengono soddisfatti i bisogni emozionali (sic) attraverso lintrattenimento, linformazione e la capacità di partecipare alla creazione di contenuti (Stephen 2005)[15]. Più coerentemente con le funzioni proprie della biblioteca, Chad e Miller (Chad-Miller 2005) analizzano il tema della rilevanza della biblioteca rispetto ai soli bisogni informativi. Sin dal titolo del loro artico Do library Matter? utilizzano il tema del ruolo delle biblioteche nella società contemporanea, messo i discussione dalla presenza di fonti informative come Google, più facilmente accessibili e apprezzate dai giovani, per prospettare la necessità di un cambiamento radicale pena la perdita di significato e di ruolo. Put simply, libraries must now begin to use these Web 2.0 applications if they are to prove themselves to be just as relevant as other information providers, and start to deliver experiences that meet the modern users expectations (Chad-Miller 2005 pag. 7)[16]. Secondo loro, benché a torto, nel mondo di Google e Amazon, le biblioteche sarebbero percepite come luoghi logori e scoloriti, pieni di libri ammuffiti, utilizzati da un numero calante di persone. Quello che rende più significativi Amazon e Google è il loro essere sempre disponibili, non in un luogo fisico, non limitati da orari di apertura. Le persone si aspettano di avere le informazioni che cercano in qualsiasi luogo, in qualsiasi momento, gratuitamente e si aspettano di poter utilizzare, modificare, scambiare tra loro quello che hanno trovato. Essendo venditori di software Chad e Miller vedono una risposta a questa situazione nella produzione di applicazioni per le biblioteche che adottino i modelli di Web 2.0. Essi abbracciano completamente la filosofia di Library 2.0 che, secondo loro, si basa su questi principi: la biblioteca è ovunque, la biblioteca è pervasiva, la biblioteca non ha barriere, la biblioteca invita alla partecipazione, la biblioteca usa sistemi flessibili. Pur riconoscendo che il termine Library 2.0 è controverso, Miller (Miller 2006a pag. 1) lo ritiene tuttavia una comoda etichetta per esprimere linsieme delle idee che nascono dallapplicazione dei principi di Web 2.0 alle biblioteche così come Web 2.0 è a sua volta unetichetta che, oltre a descrivere uninsieme di tecnologie, esprime forse uno stato della mente o unattitudine (Miller 2005 pag. 1). Miller invita bibliotecari e produttori di software ad assumere questa attitudine e a raccogliere insieme le sfide lanciate da queste idee dirompenti (Miller 2006b)[17].
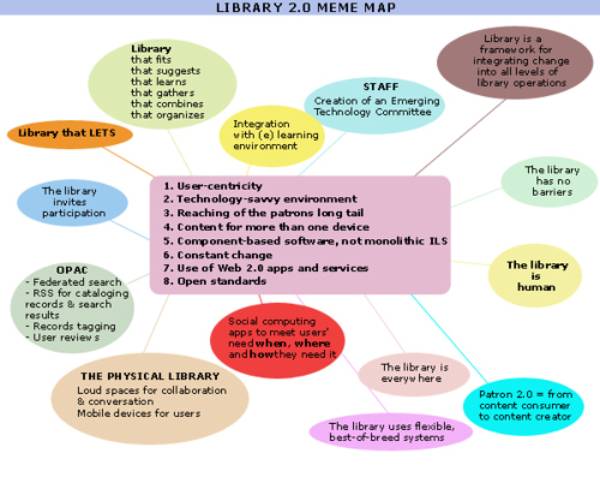
6.3 Opac 2.0Le tematiche di Web 2.0 e Library 2.0, sia negli aspetti più strettamente tecnologici sia nella filosofia di base, sono state riprese in modo significativo nellambiente delle biblioteche e sono alla base di molte sperimentazioni delle quali non è ancora possibile valutare gli esiti in termini di effettivo miglioramento dei servizi. Vediamo ora come alcune delle parole dordine di Web 2.0 possano avere relazione con il catalogo che è il fulcro attorno al quale ruotano le attività della biblioteca e i suoi servizi.
Produzione individuale e contenuti generati dagli utenti Architetture di partecipazione Uno degli aspetti legati a Web 2.0 è un diffuso interesse degli utenti alla partecipazione nei processi di creazione dei contenuti. Lo spirito del Web 2.0 non è solo fornire informazioni ma invitare gli utenti alla partecipazione, alla creazione dei propri contenuti e al coinvolgimento. Questo è possibile solo creando un ambiente tecnologico in cui la partecipazione sia resa possibile e incoraggiata. Tradizionalmente gli opac presentano agli utenti insiemi di dati estremamente strutturati e controllati, frutto di un lavoro specialistico dal quale gli utenti sono esclusi non solo in quanto produttori ma talvolta anche come fruitori diretti, non intermediati dai bibliotecari, date le difficoltà che incontrano a capire e utilizzare per la ricerca i sistemi di soggettazione e classificazione delle risorse usati dai bibliotecari. In quale modo il catalogo potrebbe essere aperto ai contributi degli utenti e trarne beneficio? Abbiamo visto che i cataloghi si stanno arricchendo di contributi provenienti anche da fonti esterne alle biblioteche, immagini, link ad altre risorse informative, recensioni ecc., sempre però attinte da fonti controllate. Nellottica di Web 2.0 / Library 2.0 gli utenti dovrebbero essere invitati a contribuire allarricchimento del catalogo con i loro commenti, le loro recensioni, i loro suggerimenti di lettura rivolti ad altri utenti o essere stimolati semplicemente a votare il gradimento delle risorse presenti nel catalogo[18]. Accanto allarricchimento dei record catalografici un contributo da parte degli utenti potrebbe venire proprio nel campo che presenta le maggiori difficoltà duso per gli utenti: la classificazione semantica delle risorse. Gli utenti potrebbero classificare le risorse attribuendo loro dei tag, cioè parole chiave o etichette che definiscono il contenuto della risorsa. Nellattività di tagging gli utenti non sono condizionati dal rispetto di un linguaggio controllato, usano invece un linguaggio spontaneo che riflette i loro gusti e la mentalità corrente e questo potrebbe rendere la ricerca attraverso i tag più intuitiva e facile rispetto alla ricerca attraverso i linguaggi strutturati presenti di solito negli opac. Dai tag vengono normalmente generate delle tag cloud, delle rappresentazioni visive dei tag attribuiti ad una risorsa, nelle quali i termini sono rappresentati con dimensioni dei caratteri proporzionali al loro peso o importanza; i tag sono dei link che portano a risorse che condividono quel particolare tag e possono costituire un punto di partenza per una navigazione del catalogo. I tag emergenti complessivamente nel catalogo darebbero il segno della direzione in cui si muovono gli interessi degli utenti.
Le problematiche teoriche che nascono dallattività di social tagging, e dal concetto di folksonomy ad essa strettamente correlato, sono alquanto complesse: accanto agli aspetti sociali si devono prendere in considerazione anche gli aspetti epistemologici legati alla capacità delle folksonomy, e in generale delle classificazioni partecipative e bottom-up, di sostituire in modo adeguato le forme classiche di organizzazione della conoscenza e per contro la capacità di queste ultime di rispondere alle necessità poste dalla rapida evoluzione e dalla crescente complessità delle conoscenze nel mondo contemporaneo. Su entrambi questi aspetti i punti di vista possono essere anche molto lontani. In ambito bibliotecario cè chi, pur riconoscendo alcuni limiti delle folksonomy, le vede come unopportunità per le biblioteche di fidelizzare gli utenti attraverso la partecipazione (Benvenuti 2007) e chi, in una prospettiva molto pertinente rispetto alle problematiche dei cataloghi delle biblioteche che qui stiamo trattando, ne evidenzia i limiti e sospende il giudizio sul ruolo dellutente come creatore dei contenuti del catalogo (Santoro 2007). Per restare nel campo degli opac delle biblioteche i limiti immediatamente percepibili di questa forma di classificazione sono laltra faccia della libertà dellutente nelluso dei tag: il rischio della scarsa qualità dovuta allignoranza dei principi elementari della catalogazione, basti pensare alla mancanza di controllo terminologico e delle relazioni tra i termini, e il rischio che lattribuzione dei tag si concentri su opere di interesse generale o di moda, lasciando scoperti ambiti documentari più di nicchia creando un'asimmetria nel catalogo. Tra gli aspetti positivi vi è la possibilità per i bibliotecari di trarre dai social tag informazioni sul linguaggio e gli interessi dei propri utenti da utilizzare sia nella catalogazione sia nelle politiche degli acquisti (Ridi 2007a pag. 262-264). Altre difficoltà nascono dal fatto che è difficile per una biblioteca raggiungere una massa critica di dati sufficiente a dare efficacia alle folksonomy. Wenzler suggerisce le biblioteche potrebbero acquistare i tag già realizzati in altri contesti come LibraryThing[19] e incorporarli facilmente nei loro cataloghi (Wenzler 2007 pag. 2). A mio parere questo farebbe perdere uno dei vantaggi di questa attività: la creazione di un linguaggio specifico di una comunità di utenti. Quanto gli strumenti per favorire i contenuti generati dagli utenti possano aumentare il valore del catalogo e non siano semplicemente un insieme di gadget è ancora da stabilire, come è ancora da verificare se esiste un reale interesse degli utenti ad arricchire il catalogo della biblioteca (Breeding 2007 pag. 14) (Wenzler 2007 pag. 2). Molti enfatizzano la necessità di riproporre nellambito delle biblioteche gli stili che gli utenti, specie le nuove generazioni, sono abituati a trovare e usare nel web pena una perdita di ruolo ed una marginalizzazione delle biblioteche[20]. Il modello della conversazione[21] che sembra essere il paradigma dominante nel web dovrebbe essere adottato dalle biblioteche e reso concreto in tutte le forme possibili consentendo la bidirezionalità del flusso informativo e un ruolo attivo degli utenti. Ladozione di questi modelli e comportamenti di per se stessa costituirebbe un valore per il catalogo. A mio parere la fiducia dellutente nel catalogo dipende dal suo essere una fonte attendibile, coerente, autorevole e indipendente, e non dovrebbe essere compromessa dalla commistione con elementi non controllati, i quali, pur utili come vie di accesso alternative, dovrebbero essere mantenuti su un piano separato e ben distinguibile dagli utenti attraverso adeguate interfacce. Restano da chiarire anche alcuni aspetti relativi alla responsabilità delle biblioteche rispetto ai contenuti immessi dagli utenti che potrebbero essere, per esempio, riproduzioni di testi o immagini altrui usati in violazione della proprietà intellettuale e delle norme relative: certo questo dubbio è in contro tendenza rispetto al concetto di fiducia che permea le comunità che usano strumenti di software sociale.
Sfruttare il potere della folla Molti dei servizi più apprezzati del web, da Google a e-Bay ad Amazon, basano parte della loro fortuna sulla capacità di sfruttare, attraverso algoritmi di aggregazione e processi di elaborazione dei contenuti generati dagli utenti, le conoscenze della massa di navigatori per aggiungere valore al servizio che offrono e massimizzare il loro profitto. Diversamente le biblioteche non hanno mai considerato i dati in loro possesso, se non quelli bibliografici, come fonti per produrre nuova conoscenza a favore dei propri utenti: dalluso di questa conoscenza potrebbero aumentare il loro profitto che consisterebbe nel massimizzare lutilizzo delle raccolte e migliorare la soddisfazione degli utenti attraverso la personalizzazione del servizio. Traditional library OPACs lack mechanisms for collecting the knowledge of library patrons. The classification schemes used to organize library collections rely on the expertise of a small group of specialists with detailed knowledge of the Dewey Decimal system, the Library of Congress classification system and the Library of Congress subject headings. Although this system works well as far as it goes, a Library 2.0 catalog that could generate additional metadata from the wisdom of library patrons would enhance the value of the OPAC. A library catalog that could point users to recommended titles in the collection based on the reading habits and descriptions of their fellow patrons would be a great benefit to many readers (Wenzler 2007 pag. 1)[22]. I modi in cui una biblioteca può fornire raccomandazioni di lettura ai propri utenti possono essere diversi. Il più semplice consiste nella presentazione di liste dei libri più presi in prestito, oppure più votati, oppure più recenti oppure quelli suggeriti da altri utenti. Si stanno tuttavia sperimentando metodi più sofisticati che adottano tecniche di collaborative filtering, un insieme di strumenti e meccanismi che consentono di generare informazioni predittive relativamente agli interessi di un insieme dato di utenti a partire da una massa ampia e indifferenziata di conoscenza raccolta analizzando le attività degli utenti che hanno usato il sistema in precedenza o altre forme di analisi e riutilizzo dei dati basate sullanalisi dei documenti (content-based filtering) o su profili utenti (rule-based filtering)[23]. Una prima forma di suggerimenti di lettura viene di solito presentata con la formula Utenti che hanno preso in prestito questo hanno preso anche . Questo metodo si basa sullanalisi dei dati di circolazione dei documenti presenti nel sistema della biblioteca. Può essere attivato in modo indifferenziato a tutti gli utenti oppure in modo personalizzato con la creazione di profili. La creazione di un profilo personale può essere fatta dallutente attraverso form da compilare a video oppure desunta da dati anagrafici, come età e sesso, o di comportamento nel sistema. In entrambi i casi richiede la conservazione in modo permanente di dati che indichino le caratteristiche dellutente sulla base di quali fornire le indicazioni di lettura.
Le problematiche che nascono nellorganizzazione di un simile servizio non sono semplici: vanno dalla scarsa quantità e dalla qualità dei dati disponibili in un ambito ristretto come è una biblioteca o un insieme di biblioteche (normalmente la quantità di dati usati nei sistemi di collaborative filtering è molto grande), alle problematiche tecniche relative a come si raggiunge un valido set di documenti da proporre come suggerimento, da una valutazione di quali sono i dati significativi per la creazione di un profilo, alle implicazioni sulle politiche di gestione della privacy degli utenti che sono legate a questi miglioramenti del catalogo. Questultimo aspetto è particolarmente significativo: i mezzi per fornire servizi più personalizzati attraverso sofisticati meccanismi di data mining delle abitudini di browsing o di lettura degli utenti esistono, è corretto che le biblioteche li usino? Quale equilibrio bisogna trovare tra privacy e offerta di nuovi servizi? Che cosa gli utenti sceglierebbero se fosse loro offerta la possibilità di valutare benefici e rischi? (Whitney-Schiff 2006) Secondo Jenny Levine gli utenti della rete sono abituati a rinunciare a parte della loro privacy allo scopo di partecipare e interagire nei diversi siti e divulgano informazioni personali in un modo che non adotterebbero mai nel mondo fisico solo al fine di condividere con altri i propri interessi. Regardless of whether librarians approve this trend or not, the truth is that we will have to adjust the entry points we provide to patron information and interaction to allow individual user to make choice about their own privacy, rather than forcing our choice upon them. In fact, this might be a golden opportunity for libraries to teach patrons how to manage their own online privacy and identities to be smart e productive digital citizens. This can happen, though, only if we acknowledge that patrons may actually want to make some of their library data public to use in ways we may not expect or condone (Levine 2007 pag. 7)[24]. Un limite dei sistemi di raccomandazione basati sui dati di circolazione dei documenti emergerà in futuro con laumento delle risorse digitali disponibili in rete: più queste cresceranno più i dati di circolazione dei documenti fisici diventeranno meno rappresentativi dei modelli di utilizzo dei documenti in biblioteca e le raccomandazioni basate su questi modelli diventeranno progressivamente meno rilevanti (Whitney-Schiff 2006 pag. 8).
Una seconda forma di suggerimenti di lettura è normalmente presentata negli opac con la formula Altri libri simili o espressioni analoghe. In questo caso si arriva alla formulazione dei suggerimenti elaborando il contenuto dei record. Il metodo applicato consiste, infatti, nellanalizzare il contenuto dei metadati bibliografici che appartengono ad un documento già individuato, scegliere i termini più importanti e formulare una nuova interrogazione: i primi risultati della nuova query, organizzati secondo algoritmi di ranking, vengono proposti come suggerimenti. Anche in questo caso le implicazioni sono notevoli: ci sono molte possibili opzioni nella scelta dei termini più significativi e diversi approcci per formulare la nuova interrogazione. Una grande difficoltà nel raggiungimento di un set di risposta significativo e coerente è data anche dal diverso livello di catalogazione dei documenti, in alcuni casi approfondito, in altri più superficiale, che si visto determinare set di risultati molto differenti (Whitney-Schiff 2006 pag. 5).
Dati su scala epica Apertura dei dati Rispetto al tema dei dati due sono gli aspetti, tra loro interconnessi, maggiormente significativi per le biblioteche: essere presenti là dove i dati vengono richiesti e consentire e praticare il mash-up dei dati, cioè rendere i propri dati disponibili perché altri li possano utilizzare aggregandoli e ricombinandoli per creare nuovi servizi e allopposto usare dati provenienti da altre fonti per creare servizi nuovi o migliorare gli esistenti servizi allinterno della biblioteca. Le persone sono oggi abituate a spendere molto del loro tempo on line. Le biblioteche hanno da tempo aggiunto alla loro presenza fisica una presenza on line attraverso i loro siti istituzionali e i web-opac, ma il loro approccio con lutenza è ancora quello di invitare lutente in biblioteca o sul sito della biblioteca o sul catalogo della biblioteca: molti sostenitori di Library 2.0 affermano che è invece importante che la biblioteca offra i suoi servizi nel luogo e nel momento in cui gli utenti ne hanno bisogno, inserendosi nel flusso di lavoro degli utenti piuttosto che pretendere che avvenga il contrario. In a pre-network world, where information resources were relatively scarce and attention relatively abundant, users built their workflow around the library. In a networked world, where information resources are relatively abundant, and attention is relatively scarce, we cannot expect this to happen. Indeed, the library needs to think about ways of building its resources around the user workflow. We cannot expect the user to come to the library any more; in fact, we cannot expect the user even to come to the library Web site any more. A corollary of this is that there is no single destination, the world has become 'incorrigibly plural'. Search engines, RSS feeds, metasearch engines: these are all places where one might discover library materials. [ ] Increasingly, we need to think of the catalogue, or catalogue services and data, making connections between users and relevant resources, and think of all the places where those connections should happen. (Dempsey 2006 pag. 3)[25]. Secondo Dempsey il catalogo deve essere staccato dal sistema informatico generale della biblioteca e integrato in altri contesti di ricerca. Non è sufficiente dunque cercare di trarre più valore dai dati bibliografici costruendo interfacce e servizi migliori che si basano sui dati strutturati del catalogo ma bisogna cercare di mescolare quei dati in altri contesti e ambienti. Questo può essere fatto, per esempio, esponendo i dati ai motori di ricerca[26] o attivando forme di syndication[27] dei dati: attraverso questi strumenti i dati del catalogo vengono portati fuori dal catalogo e resi disponibili per utenti anche diversi da quelli che normalmente li userebbero. La presenza nei luoghi dove sono gli utenti è di grande importanza: è però necessario che questa presenza sia percepita come vibrante e umana (Levine 2007): ecco allora che strumenti di instant messaging possono rendere tale la presenza del bibliotecario. Gli instant messaging sono già usati nei servizi di reference sincrono: alcuni di questi sistemi di recente sviluppo consentono di essere inseriti facilmente in ogni pagina web, scegliendo dimensioni e colori del dispositivo. Questo renderebbe possibile aprire una sessione di reference sincrono in ogni pagina del catalogo cioè proprio nel punto esatto dove lutente potrebbe aver bisogno di aiuto (Stephen 2007 pag. 15) e potrebbe quindi essere uno degli sviluppi futuri di un opac 2.0. [1] La OReilly media inc. è una casa editrice americana specializzata nel campo delle novità informatiche e tecnologiche. [2] Web 2.0 è la rete come piattaforma, che abbraccia tutti i dispositivi connessi; le applicazioni Web 2.0 sono quelle che traggono da quella piattaforma i più intrinseci vantaggi: fornendo il software come un servizio continuamente aggiornato che migliora più la gente lo usa, utilizzando e rimescolando dati provenienti da molteplici fonti, inclusi i singoli utenti, mentre forniscono i loro propri dati e servizi in una forma che consente il loro riutilizzo da parte degli altri, creando effetti di rete attraverso un architettura di partecipazione, e superando la metafora della pagina di Web 1.0 per fornire ricche esperienze allutente. [3] Per una definizione di concetti e movimenti nati da Web 2,0, oltre a quello di Library 2.0 che vedremo in dettaglio in seguito, si veda ad esempio il post del 7 gennaio 2006 di Dion Hinchcliffe (Hinchcliffe 2006) in cui sono elencati Identity 2.0, Law 2.0, Advertising 2.0, Media 2.0, Democracy 2.0, o larticolo di Andrew McAfee (McAfee 2006) su Enterprise 2.0. [4] Web 2.0 è una rivoluzione nel campo degli affari dellindustria dei computer causata dallo spostamento verso internet come piattaforma, e un tentativo di comprendere le regole del successo su questa nuova piattaforma. La principale di queste regole è: costruire applicazioni che sfruttino gli effetti di network, che migliorino più la gente le usa (E quello che altrove ho definito sfruttare lintelligenza collettiva). [5] Assolutamente no. Il Web 1.0 era tutto fatto per mettere in connessione le persone. Era uno spazio interattivo e penso che naturalmente Web 2.0 sia unespressione gergale, nessuno sa neanche che cosa voglia dire. Se per voi il Web 2.0 è blogs e wiki allora quello è da persona a persona. Ma questo è quello che si suppone che il web dovesse fare da sempre. E infatti, sapete, questo Web 2.0 significa usare gli standard che sono stati prodotti da tutte le persone che hanno lavorato sul Web 1.0. [6] Ironicamente, loriginario Web 1.0 di Tim Berners-Lee è uno dei sistemi più Web 2.0 là fuori, sfrutta pienamente il potere del contributo degli utenti, lintelligenza collettiva e gli effetti di network. E stato il Web 1.5, la bolla dotcom nella quale la gente ha cercato di trasformare il web in qualcosaltro, che ha combattuto contro internet e ha perso. [7] Il byte è una sequenza di 8 bit ed è usato come unità di misura dellinformazione o della quantità di dati. Terabyte è un valore di 240 byte (circa mille miliardi di byte). Petabyte corrisponde a 250 byte (circa 1 milione di miliardi). [8] Stavo leggendo materiale su qualcosa chiamato Library 2.0, ma i post e gli argomenti non sembravano coerenti. Ho pensato che avrei potuto raccogliere alcune affermazioni, stamparle, scorrerle, farne sommari e commenti e dare un senso a tutta la faccenda [ ] più leggevo di Library 2.0 più mi sentivo confuso, e più sentivo il bisogno di una panoramica più ampia non scritta da un sostenitore o da un evangelista. [9] I passi sono citati così come compaiono nellarticolo di Crawford. Attualmente la voce della Wikipedia è stata modificata. [10] Library 2.0 è un modello per i servizi della biblioteca che riflette una transizione nel mondo delle biblioteche nel modo in cui i servizi sono forniti agli utenti della biblioteca. Questa ridirezione sarà evidente specialmente nellofferta elettronica come la configurazione dellOpac, i servizi bibliotecari online, e in un accresciuto flusso di informazioni dallutente verso la biblioteca. Il concetto di Library 2.0 adotta quello di Web 2.0 e segue alcune delle filosofie che sono alla base di quello stesso concetto. I sostenitori di questo concetto si aspettano che alla fine il modello dei servizi di Library 2.0 sostituisca lobsoleta, unidirezionale offerta di servizi che ha caratterizzato le biblioteche per secoli. [11] Library 2.0 vede la realtà dei nostri attuali [servizi] basati sugli utenti e dice non abbastanza buoni, possiamo raggiungere più persone. Cerca di farlo attraverso un triplice approccio raggiungendo nuovi utenti, invitando la partecipazione dei clienti e affidandosi ad un continuo cambiamento. Molto di questo è reso possibile dalle nuove tecnologie, ma i servizi saranno solo parzialmente basati sulla tecnologia. [12] L2 è, secondo me, una filosofia dei servizi costruita su tre cose: la volontà di cambiare e provare nuove cose, la volontà di sottoporre costantemente a valutazione la nostra offerta di servizi, e infine, la volontà di guardare fuori dal nostro mondo in cerca di soluzioni, siano esse basate sulla tecnologia oppure no (questo è il punto in cui centra Web 2.0). [13] Va notato che molto spesso nei suoi interventi Michael Casey indica gli utenti come Customer, clienti, una scelta che sottintende un approccio non sempre condivisibile per le biblioteche pubbliche. Inoltre gli viene attribuito (Stephen 2005) linvito a misurare il ROI (return on investment) dei servizi cosa che mi sembra contraddittoria rispetto allapproccio Library 2.0 dato che proprio i servizi più personalizzati, come per esempio quelli rivolti ai disabili, sono fallimentari dal punto di vista del ROI. [14] Library 2.0 significa semplicemente rendere lo spazio (fisico e virtuale) della vostra biblioteca più interattivo, collaborativo e guidato dai bisogni della comunità. Esempi di come cominciare sono blogs, serate di giochi per i teenagers e siti collaborativi di fotografie. La spinta di base è riportare la gente in biblioteca rendendo la biblioteca rilevante rispetto a quello che essi vogliono e di cui hanno bisogno nella loro vita quotidiana rendere la biblioteca una meta e non un ripiego. [15] Per una riflessione sullopportunità di non snaturare le finalità proprie della biblioteca allo scopo di rincorrere la soddisfazione degli utenti relativamente a bisogni che non sono pertinenti si veda Ridi (Ridi 2007b). [16] Per dirlo in modo semplice, le biblioteche devono ora cominciare ad usare queste applicazioni Web 2.0 se vogliono dimostrare di essere rilevanti come altri fornitori di informazioni, e cominciare a fornire esperienze che vanno incontro alle aspettative degli utenti moderni. [17] Come sottolineato da Crawford (Crawford 2006 p. 16) alcuni bibliotecari ritengono che linteresse per Library 2.0 di aziende come Talis dovrebbe essere guardato con sospetto e la definizione dei servizi stile Library 2.0 dovrebbe essere lasciata ai bibliotecari e agli utenti. [18] Un esempio di come la biblioteca possa offrire questi strumenti è dato dal Social opac della Ann Arbor District Library <http://www.aadl.org/catalog> in cui gli utenti collaborano ad arricchire il catalogo in un ambiente estremamente personalizzato in cui possono anche fare commenti, scrivere blog post, sottoscrivere RSS feed. [19] LibraryThing, <www.librarything.com> è un sito nel quale si possono catalogare i propri libri personali catturando i data da Amazon o da altri siti, fare recensioni, attribuire tag, scrivere blog post e vedere le analoghe attività fatte sul sito da altri appassionati di libri. [20] Si veda per esempio la lista che Tim Spalding fornisce per rendere il catalogo divertente (Spalding 2006). [21] Per una precisazione del concetto di conversazione legato alla biblioteca si veda (Ridi 2007a pag. 264-267). [22] I tradizionali opac di biblioteca non hanno meccanismi per raccogliere le conoscenze degli utenti. Gli schemi di classificazione usati per organizzare le raccolte della biblioteca si basano sulle competenze di un piccolo gruppo di specialisti che hanno una conoscenza dettagliata del sistema Decimale Dewey, del sistema di classificazione e delle intestazioni si soggetto della Library of Congress. Sebbene questo sistema funzioni bene nel suo ambito, un catalogo Library 2.0 che potesse generare ulteriori metadati dalla competenza degli utenti aumenterebbe il valore dellOPAC. Un catalogo di biblioteca che potesse raccomandare agli utenti titoli della propria collezione scelti in base alle abitudini di lettura e ai commenti degli altri utenti sarebbe di grande beneficio a molti lettori. [23] Si vedano per esempio il Melvill Recomender Project della California Digital Library <http://www.cdlib.org/inside/projects/melvyl_recommender/> (Whitney-Schiff 2006) o il servizio My library di alcune delle principali biblioteche danesi (Barlach 2007). [24] Indipendentemente dal fatto che i bibliotecari approvino questo trend oppure no, la verità è che dobbiamo adeguare i punti di accesso che forniamo alle informazioni e alle interazioni degli utenti per consentire ai singoli utenti di fare scelte sulla loro privacy, piuttosto che imporre loro le nostre scelte. In realtà, questa potrebbe essere una magnifica opportunità per le biblioteche di insegnare ai propri utenti come gestire la loro privacy e identità on line per essere cittadini digitali educati e produttivi. Questo può avvenire, tuttavia, solo se riconosciamo che gli utenti possano di fatto volere che i loro dati di biblioteca siano pubblici per essere usati in modi che noi non ci aspettiamo o approviamo. [25] In un mondo pre-network, in cui le risorse informative erano relativamente scarse e lattenzione relativamente abbondante, gli utenti costruivano il loro flusso di lavoro attorno alla biblioteca. In un mondo di network, dove le risorse sono relativamente abbondanti e lattenzione relativamente scarsa, non possiamo aspettarci che questo avvenga. Le biblioteche hanno certamente bisogno di pensare a modi di costruire le proprie risorse intorno al flusso di lavoro dellutente. Non possiamo più aspettarci che lutente venga in biblioteca, di fatto non possiamo più aspettarci neanche che venga sul sito della biblioteca. Un corollario di questo è che non cè piu ununica destinazione, il mondo è diventato incorregibilmente plurale. I motori di ricerca, gli RSS feed, i metamotori di ricerc: tutti questi sono luoghi dove si possono trovare materiali librari. [ ] In modo crescente, abbiamo bisogno di pensare ad un catalogo, o ai dati e servizi del catalogo, che creano connessioni tra gli utenti e le risorse rilevanti, e pensare a tutti i luoghi in cui queste connessioni potrebbero avvenire. [26] Si veda per esempio Open WorldCat <http://www.oclc.org/worldcat/open/default.htm>. Il progetto consiste nel rendere visibili i dati del catalogo WorldCat ai motori di ricerca e siti commerciali legati ai libri che sono partner del progetto. Quando un utente esegue una ricerca sul sito di uno dei partner del progetto se le parole chiave immesse corrispondono ad un titolo presente nel catalogo WorldCat tra il set di risposta viene riportato questo titolo preceduto dalla frase Find in a Library che costituisce un link al catalogo WorldCat dove lutente potrà procedere alla localizzazione del documento. [27] Il modo più tipico in cui oggi vengono usati i feed RSS è per consentire agli utenti di ricevere le novità del catalogo o per essere aggiornati sulle nuove accessione nelle loro aree di interesse. Per una presentazione delle molteplici possibilitàdi utilizzo nei servizi bibliotecari si veda De Robbio (De Robbio 2007). |
| © ESB Forum | a cura di Riccardo Ridi | |